


Here’s a rewritten version of the article in a more easily understandable style:
—
The quality of synthetic data largely depends on the model used to generate it and the representativeness and quality of the original data. While most data analysts are familiar with the importance of original data quality, the quality of the model used to generate synthetic data deserves more attention.
Figure 1. The process of generating synthetic data with quality evaluation.
When discussing models, we’re not only talking about the algorithm itself but the entire process that helps create high-quality synthetic data. This involves some additional verification steps, like comparing model outcomes with real-world data. Figure 1 shows this process, and Figure 2 illustrates how it’s practically implemented using SAS Studio on the SAS Viya platform.
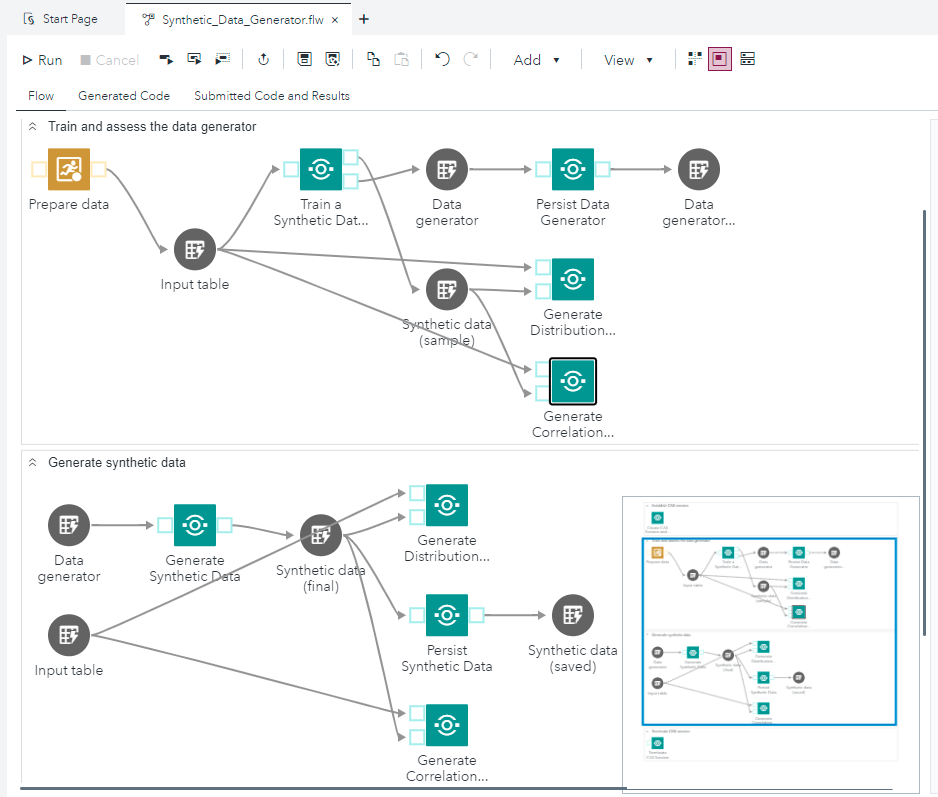
Figure 2. An example of implementing a GAN generator on the SAS Viya platform using SAS nodes available on Github.
SMOTE Model
When it comes to generating synthetic data, two popular techniques are used to address specific issues in real data. The first is SMOTE (Synthetic Minority Oversampling Technique), introduced in 2002 by Nitesh V. Chawla and others. This oversampling technique helps solve the problem of imbalanced datasets by selecting a sample and its nearest neighbors from the same group and creating new synthetic observations through interpolation. Figure 3 illustrates the basic idea of SMOTE.

Figure 3. The concept of the SMOTE method.
GAN Networks
Another versatile method involves GANs (Generative Adversarial Networks), which utilize generative AI to create synthetic data. Introduced by Ian Goodfellow and others in 2014, GANs were initially successful in image processing but have since been adapted for creating synthetic data in table format.
The CPCTGAN model (Correlation-Preserving Conditional Tabular GAN) was developed to tackle challenges in processing tabular data, such as handling both discrete and continuous variables and maintaining correlation between variables. This approach focuses on analyzing distributions and correlations to ensure synthetic data closely resembles real data.
Learning Process
The core idea of GAN-based models is fascinating because it involves a game theory concept with two players: the Generator and the Discriminator. The Generator produces synthetic data based on random input, aiming to mimic real data, while the Discriminator evaluates whether the data is real or synthetic. Training the Generator relies on the Discriminator’s errors, leading to a balance between the two. Figure 4 shows the operational process of this interaction.
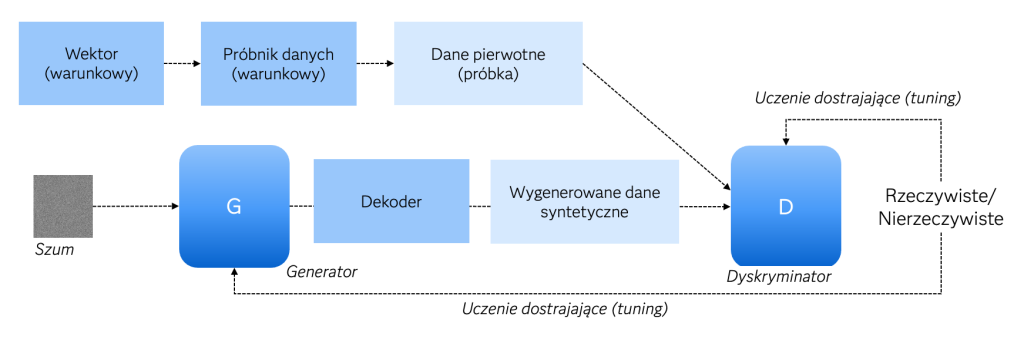
Figure 4. How GAN-based synthetic data generators work.
Synthetic Data Without Coding
Both SMOTE and CPCTGAN models are available on the SAS Viya platform, making it easier to use them without extensive coding. SAS provides ready-to-use nodes in SAS Studio, allowing users to build data flows in a low-code/no-code environment. These nodes and instructions are available on Github.
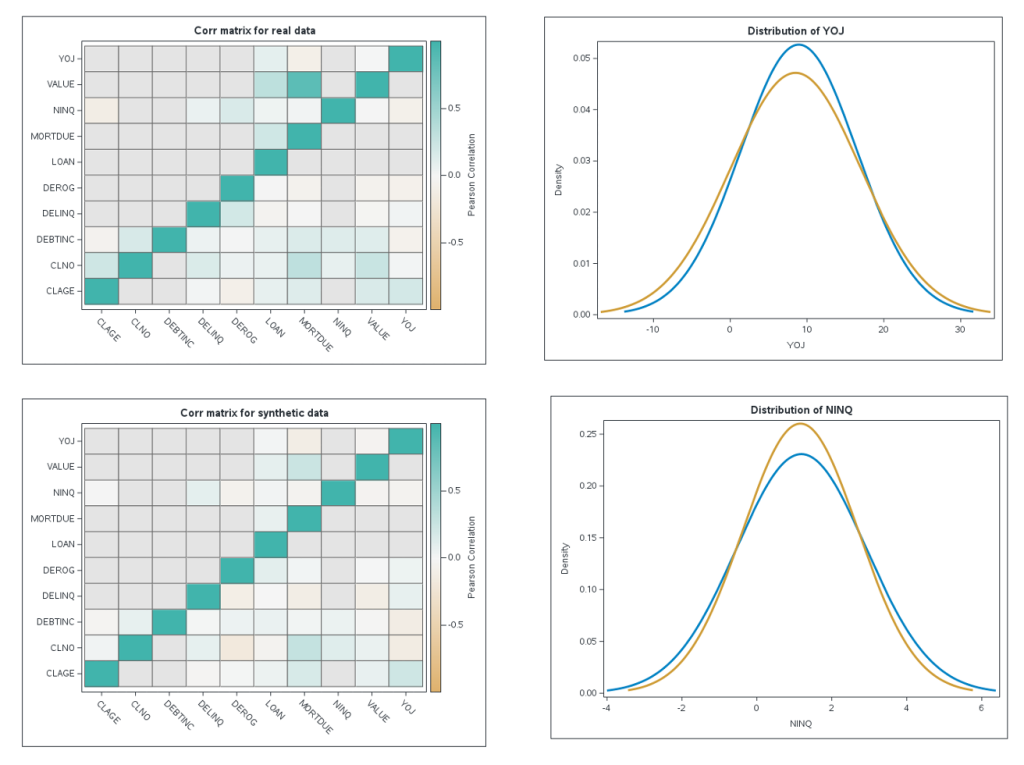
Figure 5. An example of a data set generated using GAN-based methods.
References:
1. Nitesh V. Chawla et al. (2002). “SMOTE: Synthetic Minority Over-sampling Technique.” Journal of Artificial Intelligence Research 16:321–357.
2. Ian Goodfellow et al. (2014). Generative adversarial nets. Advances in neural information processing systems, 27.







{kind=link}