


Understanding Large Language Models: Challenges and Innovations
Large Language Models (LLMs) are advanced AI systems trained on vast datasets with billions of parameters, enabling them to handle a wide range of language-related tasks. However, as tasks become more complex, these models face significant challenges in terms of interpretability and adaptability. One major hurdle is their difficulty in breaking down complex reasoning into clear, manageable steps. While current methods like Chain of Thought (CoT) prompting help by providing step-by-step examples, they rely too much on manually created examples. This makes them hard to scale and adapt to different or changing tasks, limiting their use in real-world problem-solving.
Various techniques have attempted to overcome these challenges with mixed success. For instance, Zero-Shot CoT prompting tries to eliminate the need for manual examples by encouraging step-by-step thinking. Other frameworks, like Tree of Thoughts and Graph of Thoughts, aim to enhance reasoning by organizing solutions in decision trees or interconnected graphs. These methods improve reasoning but often struggle with generalizing tasks that require implicit inferences and lack the flexibility to customize solutions for specific queries, leading to suboptimal results in complex problems.
Introducing AutoReason: A New Framework for Reasoning
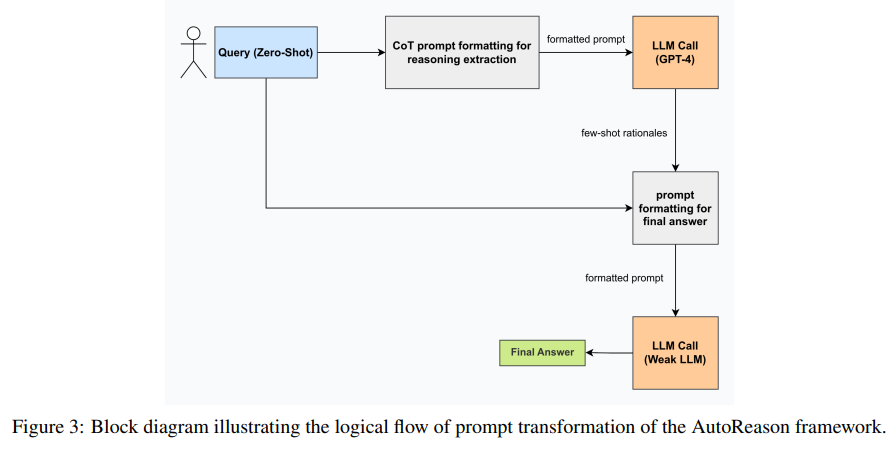
Researchers from the Izmir Institute of Technology have developed the AutoReason framework, which tackles these challenges by automating the creation of reasoning traces. This system dynamically converts zero-shot prompts into customized few-shot reasoning steps. AutoReason uses a two-level approach: a more powerful model like GPT-4 generates rationales, and a slightly less powerful model like GPT-3.5 Turbo refines these into actionable answers. This collaboration effectively bridges the gap between complex queries and clear, step-by-step solutions.
AutoReason works by first transforming user queries into prompts that encourage intermediate reasoning steps using CoT strategies. These rationales are then processed by another model to produce the final answer. For example, GPT-4 first breaks down a query into explicit rationales, which GPT-3.5 Turbo then refines. This modular method ensures clarity and interpretability, improving performance in tasks that require intensive reasoning by utilizing each model’s strengths.
Performance and Implications of AutoReason
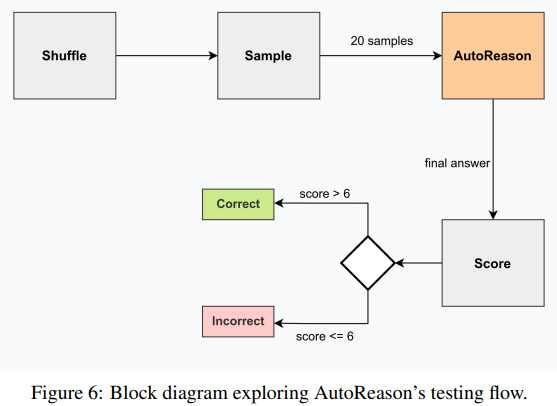
Extensive testing of AutoReason was conducted using two datasets:
StrategyQA:
This dataset focuses on implicit multi-step reasoning. AutoReason achieved a 76.6% accuracy with GPT-3.5 Turbo, a significant improvement from the baseline accuracy of 55% and an increase over the CoT performance of 70.3%. Similarly, GPT-4 showed a remarkable improvement from 71.6% baseline accuracy to 91.6% using AutoReason.
HotpotQA:
This dataset emphasizes direct factual queries, resulting in mixed outcomes. While GPT-3.5 Turbo’s accuracy improved from 61.6% to 76.6%, GPT-4 experienced a slight decrease from its baseline performance.
These results suggest that while AutoReason excels in handling complex reasoning, its impact on simpler tasks requiring direct retrieval is less significant.
Broader Implications and Future Directions
The broader implications of AutoReason lie in its ability to enhance reasoning capabilities without relying on manually crafted prompts. This automation lowers the entry barrier for applying CoT strategies, enabling scalable implementation across various domains. The modular framework also offers flexibility in adapting to task-specific complexities. For example, in real-world applications such as medical diagnostics or legal reasoning, where interpretability and precision are crucial, AutoReason provides a structured approach to managing and solving complex problems.
Key Contributions of AutoReason Research
- Developing a two-tier model approach that uses a stronger LLM to generate reasoning traces, effectively guiding weaker LLMs in decision-making.
- AutoReason significantly improves complex reasoning tasks, particularly those involving implicit multi-step reasoning steps.
- This research offers insights into the interaction between advanced LLMs and structured prompting techniques, including observations on model behavior and instances of performance regressions.
- AutoReason’s scalable and adaptable framework contributes to developing more robust and interpretable AI reasoning systems.
Conclusion
In conclusion, the AutoReason framework enhances reasoning capabilities within NLP by automating rationale generation and adapting to diverse queries. The framework demonstrates substantial improvements in multi-step reasoning tasks by automating the generation of reasoning traces and tailoring them to specific queries. While its performance in straightforward scenarios like those in HotpotQA highlights areas for further optimization, the results underscore its potential for complex problem-solving applications. This innovation bridges the gap between advanced LLMs and practical reasoning needs. Future research could explore further integrating AutoReason with other AI techniques, such as reinforcement learning, to enhance its adaptability and efficiency.
Check out the paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t forget to join our 60k+ ML SubReddit.
🚨 Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….
















{kind=link}